Chapter 3: Noise and Difference#
86400 and 24fps Psycho
Overview#
The recent emergence of 'platform services' such as Uber and Airbnb, which make use of large online databases, web services and location-based services (usually accessed via smartphone) have changed ways in which people can navigate and negotiate in cities. Moreover, Uber and Airbnb in particular reframe their workers' conception of spare time, and empty space in a dwelling as spaces for potential profit. Using the approach, tools and platforms pf platform capital – interaction with databases, APIs, and the internet via the Python scripting language – two computationally-scripted films (86400 and 24fps Psycho) analogously explore the lived realities of users of these new services. The projects create new artworks that find new relationships between the contents of existing archival film and images. 86400 represents an absurd critique of specific technology companies' tendency to convert all spare time into potential profit; 24fps Psycho represents an experimental, potentially expandable generative film which provides a potential framework for future artworks. The chapter concludes that, whilst 24fps Psycho was a failed project, computer-scripted design can and should have a critical engagement with the social realities it helps create.
Project videos#
86400 video
Palais de Tokyo | 9-11 April 2016
86400: 2-hour excerpt
Two hours of 86400, from 02:00:00-03:59:59
24fps Psycho videos
Palais de Tokyo | 9-11 April 2016
24fps Psycho: test footage
Demonstrating initial pixel-clustering
24fps Psycho: performance excerpt
At Salle 37, Palais de Tokyo, April 2016
Introduction#
This chapter explores the third of four notions of script found in this thesis: computational scripting. This mode of scripting implies the least amount of agency for the interpreter of the script (the computer); it is dictated by binary logic from which it cannot deviate. The chapter describes two projects, both of which use computational scripting and existing archival imagery to create new films. Both projects are linked thematically and formally, and were both shown at the same festival at the Palais de Tokyo. The first of the projects, 86400, used Google Images to create a film which displayed the most appropriate image for every second in a day, resulting in a 24 hour long looped film which could play in perpetuity. The second, 24fps Psycho, itself a failed experiment, displays principles which build towards the creation of a never-ending film-wandering algorithm loosely modelled on the taxi company Uber’s concept of a ‘perpetual trip.’
Context#
The time from November 2015 until April 2016 was the most intensive work period I have experienced; my residency at the Palais de Tokyo offered the opportunity to develop and exhibit ideas that I had been researching for the past few years, providing a series of deadlines, as well as institutional support, and exhibitions in which to show work. The importance of these points to my own creative practice cannot be understated: having a place to work, resources to work with, and a date to aim for is the best method I have found for transforming the many kernels of ideas that propagate my computer and sketchbook into working, functional projects which can be exhibited and provoke conversation. This was certainly the case whilst at the Palais de Tokyo: I had access to two studios, one in my live-work space at the Cité internationale des Arts, and a dedicated large, shared studio for the Pavillon artists within the Palais de Tokyo itself, as well as the support of a dedicated production and curatorial team.1
Much like the atmosphere at the Bartlett, the environment is constantly changing in the Palais de Tokyo as exhibitions and events are assembled and disassembled asynchronously, and multiple events take place near-daily. Upon leaving the studio in the evening, having been immersed in work and isolated from the rest of the building, I could just as easily be confronted by a room full of tuxedoed executives sipping champagne at an awards gala as a haute couture catwalk show, or a crowd of revellers dancing to house music, or performance poetry.2 One of the annual events that takes over the entire Palais de Tokyo is the Do Disturb festival, an eclectic celebration of dance, performance art, and design.3 Both of the projects discussed in this chapter formed part of the Do Disturb programme in April 2016.4
In the build-up to the festival, I was working on four of the seven projects featured in this thesis (86400, 24fps Psycho, Scriptych and Network/Intersect), as well as travelling to multiple countries. Despite being predominantly based in Paris, I also spent two and a half months in Chicago, a month in Korea, and several weeks in Australia.5 In order to stay in touch with family, friends, and colleagues during this time, it was necessary to remain constantly aware of the current hour in multiple time zones, as well as to jump from one mode of work (e.g. computational scripting) to another (e.g. live-action film direction) on a daily basis. This continuous switching of modes was largely facilitated through the use of computers and smartphones, which helped me keep track of shifting time zones, organise my schedule, keep in touch, collect and collate notes and ideas, and, in the case of the computer, carry out the work itself.

In the period since my doctoral research began, there have been significant changes in the way in which people use portable electronic devices. Ofcom’s 2015 Communications Market Report, released with the by-line ‘The UK is now a “smartphone society”’, shows that 66% of the adult population own smartphones, and nearly half of those state that they are ‘hooked’ on their phones.6 What’s more, these devices have changed the way people behave. The report indicates that smartphones have pervaded even the most intimate areas of personal life: ‘Half of young people aged 18-24 check their phones within five minutes of waking and two-fifths check it less than five minutes before going to sleep.’7 What’s more, many local services previously handled via personal interaction, such as ordering food or hailing a taxi, can now be done remotely via apps such as Uber. The material ramifications of app-based technology and ‘cloud computing’ are real and widespread: Barcelona, for example, has imposed heavy fines on the hotel-alternative Airbnb due to its impact raising rent prices in the city;8 the impact of taxi service Uber has been widely reported as acting aggressively in London and other cities worldwide;9 the EU courts have enacted multiple rulings regarding the collection and retention of data on European citizens and cities by Google.10 The impact of smartphone apps to facilitate, for example, navigation around a city, international communication, the ordering of food deliveries, or the scheduling of time, were especially apparent to me as I spent significant amounts of time in foreign countries. With the exception of South Korea (whose telecommunication industry is closely wedded to government, and have produced ‘local’ versions of apps such as Uber, WhatsApp, iMessage and Google Maps), I was able to use the same apps and services near-seamlessly in the UK, France, the USA, and Australia.11 Google Maps and CityMapper enabled navigation of a city; Uber enabled me to hail taxis to and from anywhere (and also order food); WhatsApp, Gmail, iMessage, FaceTime and Skype more enabled me to communicate with family, friends and colleagues across the world.12 Every social networking, messaging, or email service I used worked in the same manner as it had in London, provided I had a SIM card in my phone which enabled use of data networks. Had I been in the same position in the mid-2000s, or even the early 2010s, this would not have been the case; I remember spending hours in foreign cities searching for internet cafes in order to send messages home. In the early 2010s, I began noticing a general shift towards apps as services, and a reliance on ‘cloud’ computing, and unseen, remote databases, and in 2013-14, I began to investigate the most readily apparent of these computational companies: Google. I took particular interest in this company, as I have personally witnessed their growth and spread into many spheres of public life.
I remember the first time I heard about Google, when its sole offering was a search engine, in 1998. Still a schoolboy, a friend had told me of the ‘best’ search engine, which selected its results by machine rather than the pre-approved directory method of the other major search engines of the day.13 At the time, I thought the name was hilarious (although the humour threshold for my adolescent self was admittedly fairly low). Over time, I became a near-daily user of Google Search for homework, then Gmail, Google Docs, Google Sheets, Google Blogger, Google Calendar, Google Reader, Google Maps, Google Scholar, Google Street View, Google Books, and numerous other Google services. From the time when I was in compulsory education to today, Google have grown exponentially, with an ever-expanding and diversifying offering of products and services.
In 2009, I bought a Google Android phone. My experience of navigating London, to where I’d recently moved, changed instantly – it became nearly impossible to get lost since a geolocated phone was in my pocket (unless, of course, the phone rang out of battery). I also had continuous access to email, news, calendars, documents – and the internet. My experience of London itself was largely shaped by the technology of the time. Much of this technology came from one San Francisco-based company. In 2013 I began to research Google as a corporation. My fascination stemmed from the fact that their products and services touched such a large part of so many peoples’ lives on a daily basis, yet little is publicly known about the company itself.14 I found that, on the whole, Google are quite un-Googleable; little information is publically available about staff or corporate structure. This leads to a one-way expectation of transparency, whereby Google provides numerous services in exchange for your personal information, yet never discloses its own corporate operations. Its own tax setup is notoriously complex and subject to criticism.15
I pored through the publically-available US tax returns from 2004 until 2013 (the year the company incorporated to the last date available at the time), and built a Google Sheets spreadsheet of declared assets, incorporations, and sales of subsidiary companies.16 I made a Google Map of the addresses of company headquarters and directors’ addresses as listed on the forms in an attempt to map the locations of the company.17 It appeared that in 2011 the company had undergone a large corporate restructuring; they went from owning 28 companies in 2005, to 117 in 2010 (an acquisition rate of nearly one company per month) to owning just two companies in 2011: Google Ireland and Google Ireland Holdings. This structure is a perfect example of what the Irish Treasury call the ‘Double Irish’, a tax-avoidance measure which ‘relies on arbitrage between the different tax rules used in different countries.’18
Midway through this research, the company restructured again, part-splitting and becoming a subsidiary of the umbrella company Alphabet.19 Although I was fascinated by several things within Google, my primary interest was their ability to continually expand their reach and scope, and the public perception of what the company was. From the origins as an algorithmically-driven search company, they had become a word ubiquitous with experimentation, a data-driven approach to computing myriad things. It came as no real surprise to me that Google were exploring self-driving cars, that they had piloted schemes to fly high-speed wireless access point balloons over developing nations to provide web access, that they were digitising thousands of books, installing high-speed internet in cities in the US, or participating in numerous other activities.20
I found their self-driving cars particularly interesting.21 Whilst self-driving cars have been a serious subject of study since at least the 1930s, the computational technology to make them a mass-market reality has only recently emerged.22 Keen to project an image of harmlessness and innocence, Google’s (now Waymo’s) self-driving cars have the appearance of enlarged childrens’ toys.23 Using LiDAR scanners, the cars build a highly accurate point-cloud map of the city they are in, as seen from the cars’ perspective.24 The cars also have access to a pre-existing 3d map of the area; the cars continually compare the scene they can ‘see’ at any one moment with the one that has already been created. Any difference is something that is to be recorded and used to make calculations.25 This technique is interesting, as it relies on huge amounts of spatial data to interpret its environment, and the construction, optimisation and maintenance of huge databases. If the cars are implemented in the real world (as opposed to their current prototypical status), they may then also constitute an audacious mapping project: a millimetre-perfect three-dimensional map which is updated every time a car drives along a street.
The Google self-driving car differencing technique reminded me of Gregory Bateson’s influential lecture Form, Substance and Difference (later published as an essay).26 In the talk, Bateson lays out a clear argument that: ‘information – the elementary unit of information – is a difference which makes a difference [^original emphasis].’27 In the case of Google’s self-driving cars, anything that is found in the latest LiDAR scan that is not in the existing model is a difference – Bateson called ‘difference which occurs across time [...] “change”.’28 For Bateson, the idea of difference is key to cognition. His argument is an extension of Alfred Korzybski’s dictum the map is not the territory, (as discussed in this thesis’ introduction).29 The map that Google’s self-driving cars use is effectively a diagram of differences, changes in a territory large enough to warrant a change in the cars’ behaviour.
Another company who announced its research into self-driving cars at around the same time was Uber, the controversial app-based ride-hailing company. Formed in June 2010, and utilising the inbuilt GPS and Wi-Fi geolocation technologies (both of which are synonymous with smartphones), Uber is a service which enables users of a smartphone-based app to order a taxi to their location at any time (usually within cities).30 Taxi drivers and customers (referred to as ‘riders’) both use different interfaces within the same app to hail rides, and to find customers; the service is dependent on a large, dynamically-updating database which keeps track of all active riders and drivers at any one time.31 In a similar manner to Google, Uber practises data asymmetry with its drivers and customers; drivers are never made aware of where their next customer wants to go until they have entered the vehicle, thus ‘starting’ the trip, whereupon they are provided with their end-destination and directions for their journey (all provided via the app screen);32 the movements of all riders and drivers are also monitored at all times via a master interface the company variously called ‘Heaven’ or the ‘God View’.33 Like many other app-based companies, the method for interaction that the apps offer is an Application Programme Interface (API), a standardised protocol by which information can be passed from a central server to a device, with most of the information processing taking place on a company’s remote server.
As with Google, I became interested in Uber in 2013 for several reasons. They are controversial in London and many other cities, where they undercut pre-existing transport companies and unions, and using a purely data-driven approach to transport logistics. Besides their labour practices, whereby drivers are technically self-employed (yet ‘rides’ are near-completely controlled by the company), they company also use interesting language to describe their operations. Their founder, Travis Kalanick, uses metaphors of fluidity similar to describe their ideal operation:
Our philosophy is to always have an available ride to someone who wants it. Our mission, we like to say, is transportation as reliable as running water, everywhere for everyone.34
At the time of my moving to Paris, several articles had been published in mainstream press regarding Uber’s next, ‘audacious vision’:35 the perpetual trip.36 This expands the fluid mode of movement that Uber envision for their drivers and passengers even further: all are subject to continuous movement, with drivers picking up and dropping off passengers travelling in similar directions on an ad-hoc basis, with the goal of near-continuous movement and multiple occupation of the car by passengers.37 I became intrigued by the potential sensation of being an Uber driver on a perpetual trip – eternally moving, fed ad-hoc directions via a remote, human-less interface.38 In his presentation discussing the company’s operations in 2015, founder Travis Kalanick spent much time discussing the employment opportunities his company had created, as well as the ease with which riders could use the app, and the partnerships they were forging (and hoping to forge) with local governments, but very little time discussing the day-to-day experiences of being a driver.39 The perpetual trip struck me as a strange new form of labour, a continually-updated journey to nowhere in particular, with a continually-changing series of passengers in the drivers’ vehicle. I wanted to explore this concept metaphorically in a design project.
In order to examine the world of these forms of emerging web-technology further (and their gradual transgression into the built environment), I decided to work in the media of the technologies themselves. I began learning Python, the language that which the original Google web-crawler was built in.40 I also wanted to work with relational databases, which are the back-bone of many web services. I was also intrigued by the programming language Max, largely used by musicians and visual content creators, which offers a visual node-based mode of programming; I had seen it used by several media artists, and its diagrammatic mode of programming reminded me of the aesthetics of building electronic circuits or patches for synthesisers.41 This investigation led to the creation of two projects. The first, 86400, looks at interfacing with Google via one of their APIs and attempting to represent a specific vision of how Google Images sees time visually. The second, 24fps Psycho, is a first-attempt at creating software that creates metaphors for the Uber perpetual trip. Both of these projects create films that are too long to actually watch.
86400#
In 2010, Christian Marclay premiered a film called The Clock.42 24 hours in length, it consists entirely of excerpts from films and television programmes which features a depiction of the time on-screen, usually on a clock-face (but sometimes spoken). When exhibited, the film plays in real time, so that at any one moment the time on-screen is the real time. Being a 24-hour long montage, the audience are free to construct their own narratives and rationale connecting the films; it plays like a string-of-consciousness, the only consistent connection between the myriad segments being the representation of the time. The concept of the film resonated with me; the method of construction is similar to some of the Oulipo’s poetic and storytelling methods.
Google’s Image Search, a service which enables users to search for images, was first released in 2001.43 A web-crawler which enables users to search for images online, the early versions of the service created a large database of images found online, and categorised them according to the content of the web-page on which they were found (e.g. a caption below the image).44 Google Image Search now allows for users to search by image – instead of typing a search term in the search bar, users can drag an image from their computer. In 2011, the artist Sebastian Schmieg began experimenting with this function of the search engine, and created the first of an ongoing series of films whereby he conducts a recursive image search: uploading an image as a search, downloading the first returned image, using this as the next search – and so on. The first film in the series, Search by Image, recursively is a 12-frame-per-second video consisting of 2951 images, initiated through the upload of a transparent 400x225 pixel PNG-format image.45 The film shows a series of seemingly-related images, working through images of galaxies, cities by night, screenshots of computer games, films, graphs, catalogue product photos, diagrams, and more. At one point a stylised ‘meme’ image is on-screen for several seconds, as multiple iterations with differing text and dimensions flash onscreen for a fraction of a second each. The film simultaneously shows the diversity and multiplicity of images found on the internet. It acts as a snapshot of a time, when the unseen inferences about images caused Google Images to equate any two images to each other (performing the same search at a later date may lead to a different series of images). In a similar way to Marclay’s The Clock, I was impressed by the implicit relationship between disparate sources the audience was forced to question.
On day in early 2015, whilst teaching myself to programme in the Python language in the Bartlett studio, I decided to search for the current time on Google Images, in the form of a 24-hour clock (e.g. 12:15:32). The result was a series of almost random images. I repeated the process for several more times, loosely following the clock as it changed in real-time (although unable to perform the search at the required speed of once per second!). The images that were returned occasionally bore a direct relationship to time, but very few featured, say, a clock, or a timestamp. I enjoyed trying to work out what the relationship between each one and the time really was. I decided to make a film which would feature the image for the current time, in the HH:MM:SS format, for all 86,400 seconds in the day – but instead of searching manually, I would automate a script to search for me.
I wrote a basic Python script which would interact with the Google Images API, the programming interface that enables developers to interact with the Google Images service without the standard interface. The API was technically deprecated, meaning that it would be disabled within the near future, but was still functioning.46 There are 86,400 seconds in any day – which meant that I had a target of that number of images to return. The first task was the establishment of a data structure to hold the results of searches in a database which would make them useable at a later date.47 I established a database with two tables: searches, and images, hosted on a remote server (which meant that I could enable multiple remote computers to work on the searching simultaneously). Each search would be logged as an item in the searches database, along with its success, the IP address the search was logged from, a timestamp, and a few more items of data. If a search was successful, the images it returned would be logged in the images table, along with information that the API provided, including their original context, various associated URLs, the IP address used for the search, an image description, and the image rights (ranging from public domain to copyrighted images). Each search would return up to four images, which were all logged in the images table. The first time a search term was used, it would be for public domain images; if this search was unsuccessful, it would search for two types of Creative Commons images, and finally for all images, including copyrighted images.48

I created a relational MySQL database with two tables, searches and images. The searches table would log all searches, successful and unsuccessful, whilst the images table would store all information on any images from the searches. The Google Images API allowed for searching with multiple criteria, including the rights-levels of returned images. I decided that it would be best if initial images were in the public domain; failing this, images that had various Creative Commons rights were better than potentially copyrighted images. Each time a search for a particular time returned no results, the next search for that time would be done at a less restrictive copyright level. Each second in the day corresponded to the number of seconds it was after 00:00:00 (so 00:00:00 was 0, 00:00:01 was 1, 00:01:00 was 60, 01:00:00 was 3600, and so on). Each loop of the programme operated as illustrated in Figure 3-33.
I was limited to a certain number of images per hour, and appearing to come from each IP address. The programme would pause for a period if the API returned the error code associated with too many searches having been conducted. Each search also utilised a basic random IP address, so that the searches appeared to be coming from all over the globe. I ran the search programme overnight whilst working in London, Paris, and Chicago intermittently throughout 2015. It logged over 500,000 searches, and nearly 80,000 unique images in the first of its four best-image databases49. Towards the end of this image-scraping process, the Google Image Search API became increasingly unreliable, and eventually, it stopped working. Given the continual re-indexing of images, connections and assets that Google performs, and the inability to re-perform the same search again, the series of images that this programme recorded can be considered a snapshot of a specific aspect of Google’s indexing of images, at a specific time in history.
The final stage in the creation of the film was the assembling of the images into a film. I wrote a script which methodically downloaded all of the images in the first register (the number one search result) for every second whose image had been logged. In order not to get stuck on any one image, it downloaded multiple images simultaneously. Successful downloads were logged to the images table; after several unsuccessful attempts, an image would be marked as not available, and skipped later.50 Once saved locally, another script copied images to another folder and resized them to ensure that they fitted within a 1920x1080 pixel frame, and thus would fit into a standard HD widescreen video size (images below that size were not changed). Finally, I generated all of the timestamps for images, from 00:00:00 to 23:59:59 as transparent PNG files in Processing. I then compiled the videos so that every image stayed on-screen for one second with the time displayed in a neutral sans-serif typeface over the top. The resulting film was 24 hours in length, and featured one image per second.
The resulting film was shown in its entirety, in real-time, for three days at the Do Disturb festival at the Palais de Tokyo on the 9-11 April 2016. It was displayed on a screen of approximately 5 x 3m, at the apex of the Palais de Tokyo’s main staircase – a location every visitor would pass. Unfortunately, during the festival, I was too busy working on the next project I will describe, 24fps Psycho, to gauge much audience reaction, or even watch the whole film (indeed, I have still not watched the film in its entirety). The continuous change, a barrage of images, and the natural audience tendency to try to interpret the reasoning behind each image’s appearance, make viewing a strangely compelling, but also tiring experience. Once an image has passed, it is as if it is gone forever. The relentless one-image-per-second timing creates an ever-changing scene; it is a ‘blink-and-you’ll-miss-it’ experience. Whilst knowing that the images onscreen bear only superficial relations to each other, the audience cannot help but search for links between them. This, in a way, reflects the essential premise upon which Camus’ work is predicated (as summarised by Aronson), that ‘human beings inevitably seek to understand life's purpose [^… but …] the natural world and the human enterprise remain silent about any such purpose.’51
In April 2017, I showed the work at the School of the Art Institute in Chicago. As well as the film itself, which again played in real time, I printed a series of posters which transformed the time onscreen into a regulated grid, so that each poster was equivalent to half an hour of time. The eight posters combined and displayed the hours of peak internet usage from 19:00:00 - 22:59:59 (also known as the internet ‘rush hour’).52 I feel that the juxtaposition of the film, which portrays time as an overwhelming and relentless barrage of unpredictable images, and the posters, which present time as a ‘thing’ which can be rectilinearly ordered, abstracted and viewed from afar, created an interesting tension.


24fps Psycho#
As a condition of the residency at the Palais de Tokyo, I was granted access to extensive use of the French National Audio-visual Archives, Institut national de l'audiovisuel (INA), including a dedicated research assistant and direct access to the technology department.53 I was aware of the Palais de Tokyo’s partnership a few months before moving to Paris, and began devising a rough idea of a mechanism for a never-ending film, much like the perpetual trip that Uber was proposing before I arrived at the Palais de Tokyo.
Despite the well-ordered nature of the INA archives – the ease with which film clips could be searched, downloaded, and even edited in advance – I decided that I would not use the archive to create a film with traditional context or subject matter, but rather, to try to evoke the mental state I imagined for a driver on a perpetual trip with Uber. The drivers’ journey would likely take place in the town in which they lived; each journey would necessarily follow a logical spatial progression from one area to the next, yet the vehicle itself would be in a constant state of flux, as passengers were picked up and dropped off in any order. The driver, being only fed the information of the next collection or drop-off, would have little time to ascertain the context for each passengers’ individual journey. The city would thus become an ever-shifting series of decontextualized vignettes, a constant stream of small tasks in a continually moving vehicle. The perpetual trip reframes the driver as passenger on a journey with no end in sight, and a continual reconfiguration of bodies in each vehicle. My ambition was to recreate the sensation of this journey in filmic form, using scripted software. This was to form the prototypical software which became 24fps Psycho, as well as the basis for an as-yet-unrealised project which further realises the idea.54
Part of the inspiration behind the project came from the Charles and Ray Eames film Powers of Ten.55 The film, described as ‘A linear view of our universe from the human scale to the sea of galaxies, then directly down to the nucleus of a carbon atom’ is a meditation on the many scales at which one can view the universe.56 The ‘video’ component of the film is a square frame, surrounded by simple infographics displaying the current scale in powers of ten (100, 10-1, 10-2, etc.). Starting with an aerial view of a man lying on a picnic blanket in a park in Chicago, the camera zooms out at a consistent rate, by a factor of ten times every ten seconds.57 Thus, in the space of four minutes, the camera has shifted from being 100m (one metre) above the man, to 1024m away, with a viewpoint that has passed galaxies, stars, super nova flares, and more. The next instant the camera zooms back in to the man, and repeats the process, this time moving in rather than out, until the camera has reached a 10-14 metre zoom (0.0001 ångstroms), below the scale of atoms, which the narrator describes as the ‘limits of our understanding’.58 The film is well-known to architects; in fact, it was written with architects in mind. Within his notes on the film, Charles Eames writes: ‘Particularly in the past fifty years the world has gradually been finding out something that architects have always known – that is, that everything is architecture.’59

Although best known in filmic form, my first encounter with the film was rather different. Aged six, and passing through a subway station in Mexico City, I was enthralled by large-scale prints on the wall, approximately one every ten metres. Key frames from the film had been laid out in the station so that the experience of the scalar zooming was a spatial one, and the concepts from the film presented in such clear language that a six-year-old could grasp, and remember them. The exhibition made a strong impression, and it was only much later in life that I realised that the images had, in fact, been taken from a film. When I did finally discover the film version of Powers of Ten, I began to wonder how film could be constructed as a spatial entity. I was struck by the way that traditional celluloid film projection relies on a linear, spatialised format where each frame, onscreen for 1/24 of a second, takes up the same amount of room on the spool, and is something that must me ‘moved through’ before the next frame can be seen. Each frame has fixed dimensions, irrespective of how much ‘information’ it contains – a blank screen requires as much celluloid and takes the same amount of time as the most intricate photograph. The film can only ever move in a linear way, forwards or backwards, much like Turing’s original concept for the Turing Machine.60 The basic premise of film, that it relies on frames progressing at a rate above that of the human perception of motion, has remained unchanged since Eadward Muybridge’s experiments with photography in the 1880s.61


I wanted the project experiment and play with the spatial qualities that film contained. Often, when immersed in a film, I find myself reminded of other films and scenes – either by the composition, grading, themes, general ‘mood’, soundtrack, or any of a number of other signifiers. I started thinking about whether it would be possible to create a filmic version of hypertext, the principle envisioned by Vannevar Bush in 1945 and forming one of the foundations of the internet.62 I wanted this project to play with the inherent spatiality of film, creating a virtual map on-screen that could be navigated via the playing of films, as if the viewer were passing through space.
In order to do this, I needed a criterion by which each film clip would relate to the next, a logic by which to stitch films together. On the perpetual trip, the logic of progression could only ever be spatial: a vehicle moves through a city on a journey planned by an algorithm on a two-dimensional map. Uber vehicles being subject to the use of road maps, cars can only choose from a limited number of options at each junction (e.g. turn left or right, or continue). Traditional film, as projected in cinemas for the past century, is an established and predictable medium: it usually consists of 24 frames being projected sequentially onto a screen per second (commonly known as frames per second, abbreviated to ‘fps’), whilst one side of a celluloid film strip contains the soundtrack.63 Celluloid film has a consistent bit-rate of one regularly-sized frame every 24th of a second; a twenty-minute long blank film would occupy exactly the same amount of physical space as a twenty-minute segment from a Hollywood film.64
I decided to begin the project by attempting to find similarity between different frames in pre-existing film clips. Similarity is a vague term in computation: there are myriad methods which could be applied to rank images’ similarity to each other (this has long been the case: Marvin Minsky described ‘the problems of visual pattern-recognition’ as having ‘received much attention in recent years’ within the field of artificial intelligence in 1961).65 Not having a formal background in machine learning, I decided to find an arbitrary method for finding similarity in order that I could begin working, and testing (with the intention of later improving my detection mechanisms); I settled with analysing the colour content of film frames, reducing the complexity of images to a simple 3x3 grid. By the time I arrived in Paris, I had built a rough prototype of a scripted programme which would analyse and log the colour content of film frames.66
My initial prototype analysis software, built in Processing, took short film clips, and logged, in real-time, a variety of calculated and measured values for each frame in a film to a Comma-Separated Value (CSV) file, including:67
-
The red, green and blue (RGB) pixel values for nine points within the image (the central pixel for each rectangle if the screen were divided into a 3x3 grid)
-
Averaged RGB values across the whole image
-
Averaged RGB values across a 3x3 grid
-
Averaged RGB values for the horizontal and vertical middle line of pixels
The basic premise of the software was as a first-stage in the development process: this would enable the creation of a database of pixel values for each frame in a film, which could then be used as a basis for a form of mathematical comparison of film frames for similarity. The software also enabled a graphic interface to preview films that were reduced to 3x3 grid of either averaged pixel values, or the centremost pixel within each of the 3x3 grid rectangles. I was surprised how recognisable film clips were when reduced to this simple grid; I used footage that I had shot of driving over a bridge in Iceland, as well as the famous shower scene from Alfred Hitchcock’s Psycho to demonstrate this principle.68 I chose these scenes initially simply because I had them to hand whilst I was writing the programme; however, upon showing the demonstration software to an audience, I was struck by just how recognisable the film still was. I also realised that in using a black-and-white film, the level of computation my simple programme would have to perform would be one-third of that of a colour film.
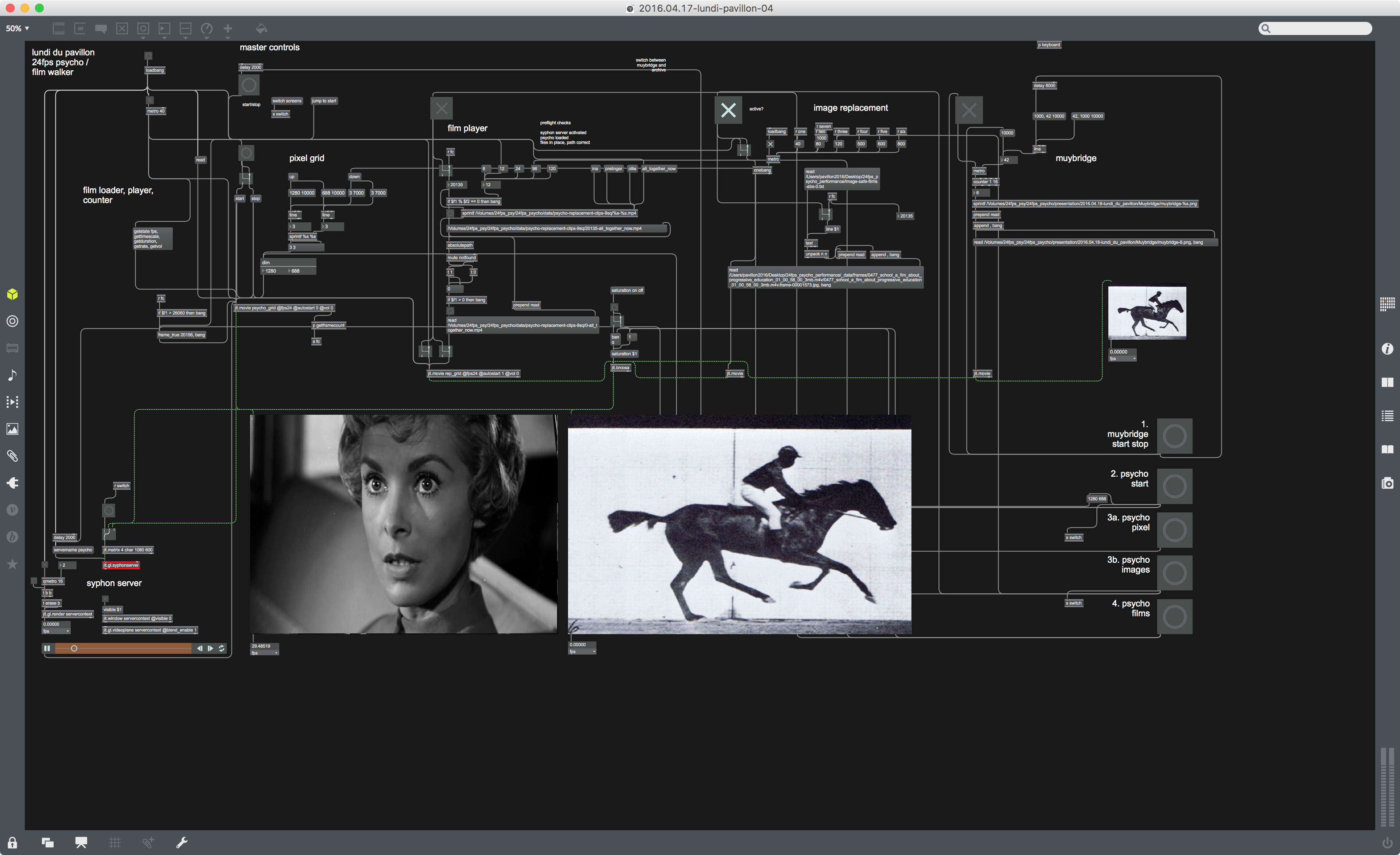
I started to download films from the INA and Prelinger Archives.69 INA’s research department had granted me access to a collection of their 1940s-1960s newsreels. I particularly liked the aesthetic of the Prelinger Archives: American films, often home movies, public television broadcasts, or corporate films.70 I used a Python script with the ffmpeg library to split every Prelinger film into its constituent frames, a new version of my Processing script – this time rebuilt in Python, using the Pillow image-processing library – to create a database of the colours within each image. In order to test how closely my system managed to organise similarity, I started to use my databases with Max, and the source film Psycho, to replace each frame in the original film with a ‘similar’ frame from the Prelinger archives.

At this stage, I had a meeting Fabien Danesi, a curator at the Palais de Tokyo, who had seen my presentation at the Tokyo Arts Club. I showed him the updated software, and described the ambition I had for the project. He told me about Douglas Gordon’s 1993 installation 24 Hour Psycho, an artwork which served as the setting for, and had been described at length, in the novel Point Omega.71 In 24 Hour Psycho, Gordon had slowed the film Psycho down to the extent that it took 24 hours to play the entire film (meaning that the film plays at approximately two frames per second); DeLillio’s description of the film, woven throughout the novel, is as a series of images whose meanings have been transformed; every minor inflection made by an actor can be examined in excruciating detail.
At this time, working in the gallery’s studio every day, I was acutely aware of the location of the Palais de Tokyo in Paris. It is housed in one of the few remaining buildings in Paris from the 1937 World Exposition. For years the building was empty, serving various (mostly storage) purposes until it re-opened in 2003. Its exterior is a mirror image of the Musée d'Art Moderne de la Ville de Paris, which is housed on the other side of a multi-level courtyard featuring a large colonnade and a pond. In the midst of the conversation with Fabien, we had watched an excerpt of a BBC Documentary about Douglas Gordon made in the 1990s, which featured an interview with the artist on the colonnade, and the installation of work in the museum opposite us.72 Gordon had, in fact, installed 24 Hour Psycho in the Musée d'Art Moderne in the year of its creation.73
By this time, it had become apparent that the computational work required to translate the notion of the perpetual trip into film in the manner I wished within the period of my artist residency; it would require significant investment in machine learning skills. The data operation to choose the most appropriate match to that currently onscreen, from a potential pool of millions of images, 24 times a second, is complex, and was in hindsight beyond my skills at the time. However, I was keen to develop and show a version of the project, and had received positive feedback after demonstrating the prototype software in November. Fabien proposed that my version of the frame-replacement software could be shown in the Do Disturb festival. I decided that using Psycho as a base film would work; in the tests I’d worked on in the studio, large portions of the film remained legible, both after the original images were reduced to a 3x3 grid of greys, and then after my image-replacement algorithm had been used.
I worked on 24fps Psycho in between multiple other projects (86,400, Network / Intersect, and Scriptych), in multiple countries. Most of the coding took place during the month-long stay in Korea, whilst editing and setting up Network/Intersect for installation at the Seoul Museum of Art (see chapter 4). The installation date for Network/Intersect was the 30th March 2016, and the opening was on the 5th April. It required editing until the last minute. I flew back to Paris the morning after the opening, and worked on 24fps Psycho for its performances on the 9th to the 11th April. I use the term ‘performance’ here because the process behind the film was a performance; the computation all took place in near real-time, and each screening was different.
The setup of the performances was as follows. The performances took place in the Palais de Tokyo’s Salle 37, an art deco cinema room dating back to the gallery’s construction. Three screens occupied the room; on the central screen, the film Psycho was projected onto the central screen. After the title sequence, the image became ‘pixelated’ into smaller and smaller resolutions, until after four seconds, the screen simply showed a 3x3 grid with the average colours from the nine equal areas onscreen. The resulting colours were then used to query the database I had collated of the frames from all of the Prelinger Archive films. The image that was most similar to these averages was then displayed, in black-and-white on the two screens to either side of the main screen.
The first screening, however, was a disaster. The cinema projection booth had been refurbished multiple times, and was wildly impractical; where most projection booths have a means of viewing the screen they are projecting onto, this area had at some point been bricked up; viewing the screens could only be achieved by climbing onto the desk in the booth. My allocated screening times were between other performances and film screenings, and there was a very short setup time. Because the processing was happening live (and could change each time it was screened), the performance relied on the use of a high-powered iMac that the Pavillon studio owned. However, the rigging company who had been brought in to install AV equipment had not brought the appropriate adaptors (despite having had a comprehensive tech setup runt-though the day before), so at the last minute, instead of checking each part of my set-up methodically, I spent the entire time trying to locate an adaptor, then reconfiguring the specialist software I had to use to interface with the projectors. At this time, the technicians all disappeared. The screening restarted several times due to a string of technical errors. At one point, as it became clear that there was an issue with the projection interface, I had to write a patch during the performance.74 Part of the nature of work that involves experimental computation involves accepting a degree of technical error; however, I have never had such a catalogue of issues with a single project. The sensation of such a failure is crushing.
By the time of the next screening, however, I had been able to robustly rebuild almost the entire project to be more resilient in case of an error such as projector failure. Being subject to what felt like every possible failure made the second performance far better. Since the software had been extensively rebuilt, it was also my first chance to see the film the entire way through (I had worked on selected sections before), and I became a member of the audience in the screening room. The imagery, although not continually updating at 24 frames per second (due to memory lags) did have a beguiling effect similar to 86400. Although no image existed onscreen for long enough to perceive in its entirety, different frames from the same films featured onscreen repeatedly; one motif repeated was a Richard Nixon press conference, and many distinctively 1950s-60s elements of American life appeared onscreen. Initially overwhelming to watch, the barrage of continually changing images, faster than comprehension would allow, became a steady stream of noise; the difference between individual images became a constant, removing the perception of difference.
Project learnings#
This chapter presented two projects which both exclusively used computer scripting and archival content to create new films. An important part of the way that I work is to continually experiment with new media and materials, and it is inevitable that sometimes these experiments do not work in the way that I would like. This was the case with 24fps Psycho. However, I did learn a lot from the project.
One of the problems with the project was the conflation of ideas which caused the focus of the work to shift. What started as a piece of test footage (the film Psycho) became the core focus of the work; rather than being a project trying to create an endless film, creating a metaphor for the experience of a perpetually travelling driver, it became software that overlaid new content onto the top of an existing film. The formal quality of the film did partially hint at the absurd. At the screenings of 24fps Psycho, much of the content of the original film was included: the distinctive soundtrack, with its score by Bernard Herrmann, as well as the colour content, albeit in pixelated form. When confronted with these elements, as well as the new images being projected alongside, the audience attempted to find meaning in the entire assemblage. Inevitably, the experience was incomprehensible; the stream of imagery was relentless and unrelated to the film itself (besides the visual similarity of 1950s/1960s American films). The experience was ultimately meaningless – which is a partial absurd success.
The film also highlighted the Batesonian ideas of noise and difference. Initially, confronted with the baffling, continuous reel of images, experiencing the film was tiresome. However, after a few moments the content of the imagery ceased to be tiring; my mind had realised that the imagery was all noise, rather than information. I was surprised to find that 86400 is actually more challenging to watch, as its framerate of one image per second is just long enough to make connections between one image and another, whereas the images in 24fps Psycho begin to merge into one another very quickly.
One of the major compromises in 24fps Psycho was the quality of the computational processes themselves. It became apparent early on that the computational techniques required to create a similarity-seeking computational script which would be recognisable to a person, rather than a machine, were too advanced for the level of programming knowledge I had at the time. I have since learnt a number of technical skills which would have made the project far more computationally viable. The continuous technical errors that struck the first performance were crushing; however, this is also a reflection of the fragility of working in a purely computational medium. Whilst creating work of this nature is enjoyable, there is a lack of tangibility which feels restrictive with purely digital projects; there is no object or thing to point to once the performance is done. The platform-dependence of working with computer scripts is also a shortcoming of the medium: the files used to create the piece will likely not function in a few years’ time.
I do not feel as though I fulfilled the original brief I set myself with this project, of exploring the sensation of being a perpetual trip driver. As experimentation is part of my working practice, so is a lack of ‘closure’, particularly when I do not feel an idea has been resolved. The framework of 24fps Psycho, and the skills that I have learnt from the project, will inevitably find their way into new works in the future.
However, by providing User Content to Uber, you grant Uber a worldwide, perpetual, irrevocable, transferable, royalty-free license, with the right to sublicense, to use, copy, modify, create derivative works of, distribute, publicly display, publicly perform, and otherwise exploit in any manner such User Content in all formats and distribution channels now known or hereafter devised (including in connection with the Services and Uber’s business and on third-party sites and services), without further notice to or consent from you, and without the requirement of payment to you or any other person or entity. Uber, ‘Legal: Terms and Conditions (GB)’, Company website, Uber, (23 August 2016), https://www.uber.com/legal/terms/gb/.
We might think of liquids in motion, structured by radiating waves, laminal flows and spiralling eddies. Swarms have also served as paradigmatic analogues for the field concept: swarms of buildings that drift across the landscape. There are no platonic, discrete figures or zones with sharp outlines. Within fields only regional field qualities matter: biases, drifts, gradients, and perhaps conspicuous singularities such as radiating centres. Deformation no longer spells the breakdown of order, but the inscription of information. Orientation in a complex, differentiated field affords navigation along vectors of transformation. The contemporary condition of arriving in a metropolis for the first time, without prior hotel arrangements and without a map, might instigate this kind of field-navigation. Imagine there are no more landmarks to hold on to, no axes to follow, no more boundaries to cross. Patrik Schumacher, ‘Parametricism: A New Global Style’, in Digital Cities AD, ed. Prof Neil Leach, 4th ed., vol. 79, Architectural Design 4 (Wiley, 2009), 14. Schumacher also copies whole sections of this quote verbatim into Patrik Schumacher, The Autopoiesis of Architecture. Vol. 1: A New Framework for Architecture (Chichester: Wiley, 2011), 421–23.
-
The Palais de Tokyo Pavillon production team consisted of Ange Leccia (Pavillon founder and director), Fabien Danesi (programme director), Chloe Fricout (coordinator and production manager), Justine Hermant (production support), Justine Emard (technical support), Marilou Thiébault (intern), Caterina Zevola (production support). ↩
-
All of these events, and many more, really occurred. The continual change creates an atmosphere which feels as though anything could happen at any moment. ↩
-
Palais de Tokyo, ‘Do Disturb. Festival Non-Stop: Performance, Danse, Cirque, Design...’, Palais de Tokyo EN, 13 June 2016, http://www.palaisdetokyo.com/en/event/do-disturb-0. The inaugural festival was in 2015. ↩
-
Curated by Vittoria Matarrese. ↩
-
My partner had recently started working at the University of Chicago; the Palais de Tokyo’s Pavillon programme included a month spent in Seoul Museum of Art’s Nanji residence, where much of the work for 24fps Psycho, and the post-production work for Network/Intersect, the focus of chapter 4 of this thesis, took place. ↩
-
Ofcom, ‘The Communications Market Report: United Kingdom’, Ofcom, 30 September 2016, https://www.ofcom.org.uk/research-and-data/cmr/cmr15/uk; Ofcom, ‘The Communications Market Report’ (Ofcom, 6 August 2015), 6. 48% of smartphone users rate themselves 7/10 or higher in describing how ‘hooked’ they are to their phones (rising to 61% for 16-24 year olds). ↩
-
Ofcom, ‘The Communications Market Report’, 6 August 2015, 6. ↩
-
B.R., ‘Barcelona Hits Airbnb with a Hefty Fine’, The Economist, 25 November 2016, http://www.economist.com/blogs/gulliver/2016/11/clampdown-catalonia. ↩
-
Sam Knight, ‘How Uber Conquered London’, The Guardian, 27 April 2016, sec. Technology, https://www.theguardian.com/technology/2016/apr/27/how-uber-conquered-london. ↩
-
See, for example, the Court of Justice of the European Union’s ruling on the ‘Right to be Forgotten’, a law enabling European citizens to remove personal information from internet search results Court of Justice of the European Union, ‘Judgment in Case C-131/12 Google Spain SL, Google Inc. v Agencia Española de Protección de Datos, Mario Costeja González’, Press Release (Luxembourg: Court of Justice of the European Union, 13 May 2014); European Commission, ‘Factsheet on the “Right to Be Forgotten” ruling’ (European Commission, 8 July 2014), http://ec.europa.eu/justice/data-protection/files/factsheets/factsheet_data_protection_en.pdf.; Swiss data laws Anita Greil and Katharina Bart, ‘Swiss Court to Rule on Google Street View’, Wall Street Journal, 24 February 2011, sec. Tech, http://www.wsj.com/articles/SB10001424052748703408604576163770758984178. ↩
-
This is the case with multiple countries where a non-Latin alphabet is used; China’s WeChat service, for example, enables far higher functionality than the equivalent European or American apps. Charles Arthur, ‘WeChat: Want an App That Lets You Do Everything at Once?’, The Guardian, 15 February 2016, sec. Technology, https://www.theguardian.com/technology/2016/feb/15/multifunction-apps-charles-arthur. ↩
-
Google, Inc., Google Maps, version 4.30.54, iOS (Google, Inc., 2017); Citymapper Ltd., Citymapper, version 6.15, iOS (London: Citymapper Ltd, 2017); Uber, Uber, version 3.243.3, iOS (Google, Inc., 2017); WhatsApp Inc., WhatsApp, version 2.17.21, iOS (WhatsApp Inc., 2017); Google, Inc., Gmail, version 5.0.17049, iOS (Google, Inc., 2017); Apple, Inc., iOS 10, version 10.3.2, iOS (Apple, Inc., 2017); Skype Communications S.a.r.l, Skype, version 6.35, iOS (Skype Communications S.a.r.l, 2017). Note that iMessage and FaceTime are part of iOS 10. ↩
-
For example, the other major search engines (including Lycos, Ask Jeeves, Yahoo and America Online) and relied on human-ranked search results via directory-style searches. The first web-crawler was Matthew Gray’s World Wide Web Wanderer in 1993. Aaron Wall, ‘History of Search Engines: From 1945 to Google Today’, Search Engine History, accessed 7 May 2017, http://www.searchenginehistory.com/. ↩
-
Google received 46 million UK visitors in March 2015; the population of the UK was estimated to have been 65 million in June of the same year. Ofcom, ‘The Communications Market Report’, 30 September 2016, 16; Emily Shrosbree, ‘Population Estimates for UK, England and Wales, Scotland and Northern Ireland: Mid- 2015’, Statistical Bulletin (Office for National Statistics, 23 June 2016), 2, https://www.ons.gov.uk/peoplepopulationandcommunity/populationandmigration/populationestimates/bulletins/annualmidyearpopulationestimates/mid2015. ↩
-
See, among numerous other reports: Kamal Ahmed, ‘Starbucks, Google and Amazon Grilled over Tax Avoidance’, BBC News, 12 November 2012, sec. Business, http://www.bbc.com/news/business-20288077; Sam Schechner and Stephen Fidler, ‘Google Strikes Deal With U.K. Tax Authority’, Wall Street Journal, 23 January 2016, sec. Tech, http://www.wsj.com/articles/google-in-talks-to-settle-european-tax-disputes-1453484192; Sam Schechner, ‘Google’s Tax Setup Faces French Challenge’, Wall Street Journal, 8 October 2014, sec. Tech, http://www.wsj.com/articles/googles-tax-setup-faces-french-challenge-1412790355. ↩
-
I searched the US Securities and Exchange Commission’s EDGAR Company filings for all of the available 10-K annual summary reports, and paid particular attention to section 21, which lists all subsidiary companies. Google Inc., ‘10-K Form #0001193125-05-065298’, 30 March 2005, https://www.sec.gov/Archives/edgar/data/1288776/000119312505065298/dex2101.htm; Google Inc., ‘10-K Form #0001193125-06-056598’, 16 March 2006, https://www.sec.gov/Archives/edgar/data/1288776/0001193125-06-056598.txt; Google Inc., ‘10-K Form #0001193125-07-044494’, 1 March 2007, https://www.sec.gov/Archives/edgar/data/1288776/0001193125-07-044494.txt; Google Inc., ‘10-K Form #0001193125-08-032690’, 15 February 2008, https://www.sec.gov/Archives/edgar/data/1288776/0001193125-08-032690.txt; Google Inc., ‘10-K Form #0001193125-09-029448’, 13 February 2009, https://www.sec.gov/Archives/edgar/data/1288776/0001193125-09-029448.txt; Google Inc., ‘10-K Form #0001193125-10-030774’, 12 January 2010, https://www.sec.gov/Archives/edgar/data/1288776/0001193125-10-030774.txt; Google Inc., ‘10-K Form #0001193125-11-032930’, 11 February 2011, https://www.sec.gov/Archives/edgar/data/1288776/0001193125-11-032930.txt; Google Inc., ‘10-K Form #0001193125-12-174477’, 23 April 2012, https://www.sec.gov/Archives/edgar/data/1288776/0001193125-12-174477.txt; Google Inc., ‘10-K Form #0001193125-13-028362’, 29 January 2013, https://www.sec.gov/Archives/edgar/data/1288776/0001193125-13-028362.txt; Google Inc., ‘10-K Form #0001288776-14-000020’, 11 February 2014, https://www.sec.gov/Archives/edgar/data/1288776/0001288776-14-000020.txt. ↩
-
Predictably, the tax and company directors all lived within 30 minutes’ drive of the Google Headquarters in Mountain View, California. ↩
-
Business Tax Team, ‘Tax Strategy Group 2014: Corporation Tax Policy’, Corporation Tax Policy (Dublin, Ireland: Department of Finance, 2014), 7, http://www.finance.gov.ie/sites/default/files/TSG%201311.pdf. The Treasury report describes the exact setup that Google employed: A ‘US Parent’ company (e.g. ‘X Incorporated’) owns an ‘Irish Registered Non-Resident Company’ (e.g. ‘X Ireland Holdings), which in turn owns a ‘Substantive Irish Co[^mpany] registered and tax resident in Ireland’ (e.g. ‘X Ireland Ltd.’). There is then a complex arrangement over ownership of goods and services, and royalty payments – see Ibid. ↩
-
The restructuring was announced via Larry Page, ‘Alphabet’, Alphabet, 10 August 2015, https://abc.xyz/. ↩
-
Neal E. Boudette, ‘Building a Road Map for the Self-Driving Car’, The New York Times, 2 March 2017, https://www.nytimes.com/2017/03/02/automobiles/wheels/self-driving-cars-gps-maps.html; Conor Dougherty, ‘Hoping Google’s Lab Is a Rainmaker’, The New York Times, 15 February 2015, https://www.nytimes.com/2015/02/16/business/google-aims-for-sky-but-investors-start-to-clamor-for-profits.html; Stephen Heyman, ‘Google Books: A Complex and Controversial Experiment’, The New York Times, 28 October 2015, https://www.nytimes.com/2015/10/29/arts/international/google-books-a-complex-and-controversial-experiment.html; Conor Dougherty, ‘Two Cities With Blazing Internet Speed Search for a Killer App’, The New York Times, 5 September 2014, https://www.nytimes.com/2014/09/06/technology/two-cities-with-blazing-internet-speed-search-for-a-killer-app.html. ↩
-
Google’s self-driving car research has been transferred to a company called Waymo, owned by Google’s parent company Alphabet. Darrell Etherington and Lora Kolodny, ‘Google’s Self-Driving Car Unit Becomes Waymo’, TechCrunch, accessed 7 May 2017, http://social.techcrunch.com/2016/12/13/googles-self-driving-car-unit-spins-out-as-waymo/. ↩
-
‘“Phantom Auto” to Be Operated Here: Driver-Less Car to Be Demonstrated About City Streets Next Saturday – Controlled Entirely by Radio.’, The Free Lance-Star, 18 June 1932; Michael Kidd, Key to the Future (General Motors; Dudley Pictures Corporation, 1956), https://www.youtube.com/watch?v=F2iRDYnzwtk. ↩
-
Early prototypes were built using golf buggies. ↩
-
LiDAR is a scanning technology that enables often sub-millimetre accurate 3d scans of an area based on the reflections of a laser across a spinning angled mirror. Ron Amadeo, ‘Google’s Waymo Invests in LIDAR Technology, Cuts Costs by 90 Percent’, Ars Technica, 10 January 2017, https://arstechnica.com/cars/2017/01/googles-waymo-invests-in-lidar-technology-cuts-costs-by-90-percent/. There are also numerous other technologies that contribute to the car. ↩
-
Erico Guizzo, ‘How Google’s Self-Driving Car Works’, IEEE Spectrum: Technology, Engineering, and Science News, 18 October 2011, http://spectrum.ieee.org/automaton/robotics/artificial-intelligence/how-google-self-driving-car-works. ↩
-
Gregory Bateson, ‘Form, Substance, and Difference’, in Steps to an Ecology of Mind, 13. printing. (Ballantine, 1985). ↩
-
Ibid., 460. ↩
-
Ibid. ↩
-
Alfred Korzybski, Science and Sanity: An Introduction to Non-Aristotlian Systems and General Semantics, Fifth edition, second printing (Brooklyn, N.Y., USA: International Non-Aristotelian Library, Institute of General Semantics, 2000), 58. Bateson invokes Alfred Korzybski’s dictum the map is not the territory, an argument that there is a distinction between the world as it exists and the human perception of it due to the limitations of sensory perception (Gregory Bateson, ‘Form, Substance and Difference’, in Steps to an Ecology of Mind: Collected Essays in Anthropology, Psychiatry, Evolution, and Epistemology (Jason Aronson Inc, 1987), 455.). Korbyski originally stated ‘A map is not the territory it represents, but, if correct, it has a similar structure to the territory, which accounts for its usefulness.’ This is an idea that is echoed multiple times in the work of Jorge Luis Borges, perhaps most famously in the short fictional story On Exactitude in Science, in which a 1:1 scale map of an empire was created atop the empire itself. Later generations discovered ‘that vast Map was Useless’, and left it to ruin in the West of the empire. Jorge Luis Borges, ‘On the Exactitude of Science’, in Collected Fictions, trans. Andrew Hurley (New York: Penguin, 1998), 325. ↩
-
Travis Kalanick, ‘Uber and Europe: Partnering to Enable City Transformation’ (Lecture, Digital-Life-Design (DLD), Munich, Germany, 18 January 2015), https://www.youtube.com/watch?v=iayagHygV0Q. ↩
-
The company uses a tool the Guardian titles ‘Heaven – the Uber-eye view of all the cars active in the city’ to monitor the location of all of its active drivers. (Knight, ‘How Uber Conquered London’.) Uber themselves call this the ‘God View’ (see Voytek, ‘Mapping San Francisco, New York, and the World with Uber’, Uber Global, 16 May 2011, https://newsroom.uber.com/uberdata-mapping-san-francisco-new-york-and-the-world/; Erick Schonfeld, ‘Uber CEO On His “Official” NYC Launch: “Congestion Is A Bitch” (Video And Heatmaps)’, TechCrunch, 4 May 2011, http://social.techcrunch.com/2011/05/04/uber-screenshots-video/.) ↩
-
In addition to the continuous tracking of users’ location whilst using the app, the Uber terms and conditions for UK-based customers state: ↩
-
Knight, ‘How Uber Conquered London’; Voytek, ‘Mapping San Francisco, New York, and the World with Uber’. In the latest version of the app, a user cannot opt-in to sharing their location only when the app is in use; they must either always or never enable location services. ↩
-
Kalanick, ‘Uber and Europe: Partnering to Enable City Transformation’. ↩
-
Uber Newsroom, ‘Uber’s New BHAG: uberPOOL’, Corporate blog, Uber Global, (2 February 2015), https://newsroom.uber.com/ubers-new-bhag-uberpool/. ↩
-
Knight, ‘How Uber Conquered London’. This is also mentioned on Uber’s blog (Uber Newsroom, ‘5-Year Anniversary Remarks from Uber CEO Travis Kalanick’, Corporate blog, Uber Global, (3 June 2015), https://newsroom.uber.com/5-years-travis-kalanick/.) as well as in Kalanick’s keynote speech Kalanick, ‘Uber and Europe: Partnering to Enable City Transformation’. ↩
-
For more on the Perpetual Trip concept, see Kalanick, ‘Uber and Europe: Partnering to Enable City Transformation’. The idea of this kind of fluidity is aligned with neoliberal market ideals; Spencer discusses (one of the originators of neoliberal thought) Michael Polayni’s discussion of fluids as a basis for organisational structures (Douglas Spencer, The Architecture of Neoliberalism: How Contemporary Architecture Became an Instrument of Control and Compliance (Bloomsbury Publishing, 2016), 28–29.), whilst for Schumacher fluidity is a central tenet of his organisational and market ideals: ↩
-
The theme is similar to the lack of control displayed in the Godot Machine of chapter 1. Note that Nathan Moore also discusses the idea of the continual movement of bodies as a mode of examining power and control (and invokes Gregory Bateson) in Diagramming Control. Nathan Moore, ‘Diagramming Control’, in Relational Architectural Ecologies: Architecture, Nature and Subjectivity, ed. Peg Rawes, 1st ed. (Abingdon, Oxon: Routledge, 2013), 58. ↩
-
Kalanick, ‘Uber and Europe: Partnering to Enable City Transformation’. ↩
-
Sergey Brin and Lawrence Page, ‘The Anatomy of a Large-Scale Hypertextual Web Search Engine’, Computer Networks and ISDN Systems, Proceedings of the Seventh International World Wide Web Conference, 30, no. 1–7 (April 1998): 113, doi:10.1016/S0169-7552(98)00110-X. ↩
-
Cycling ’74 and IRCAM, Max 7, version 7.3.1, Apple Macintosh (Cycling ’74 / IRCAM, 2016). ↩
-
Christian Marclay, The Clock, Film, installation, 15 October 2010. ↩
-
Andrew Zipern, ‘News Watch: A Quick Way to Search For Images on the Web’, The New York Times, 12 July 2001, sec. Technology, http://www.nytimes.com/2001/07/12/technology/news-watch-a-quick-way-to-search-for-images-on-the-web.html. ↩
-
Google now analyse images using other methods, as demonstrated in their Cloud Platform Vision API. ‘Vision API - Image Content Analysis’, Google Cloud Platform, 2 December 2015, https://cloud.google.com/vision/. ↩
-
Sebastian Schmieg, Search by Image, Recursively, Transparent PNG, #1, 12fps video, script, 9 December 2011, https://vimeo.com/34949864. ↩
-
This is one of the perils of working with API-based services: at any point the service provider could decide to turn the service off. The shut-down of the Google Images API appears to have been part of the much larger corporate restructuring that happened in 2011, when multiple services and APIs, including Google Labs, Google Buzz and Google Talk, were disabled. ↩
-
Note – this is strictly against the Google Images terms of use: Note: ‘The Google Image Search API must be used for user-generated searches. Automated or batched queries of any kind are strictly prohibited.’ Google, ‘JSON Developer’s Guide | Google Image Search API (Deprecated)’, Google Developers, 28 May 2015, https://developers.google.com/image-search/v1/jsondevguide. ↩
-
This resulted in a large number of public-domain images being found; largely from image public archives (e.g. NASA, Flickr’s The Commons, etc). ↩
-
The image search returns up to four ‘top hit’ images. These are returned as an array of four images, numbered from 0-3. The resultant film was constructed of images from the first result (register 0). ↩
-
This happened with quite a few images. Images often become unavailable online as servers change ownership, websites shut down, etc. ↩
-
Ronald Aronson, ‘Albert Camus’, ed. Edward N. Zalta, The Stanford Encyclopedia of Philosophy (Metaphysics Research Lab, Stanford University, 2017), 3, https://plato.stanford.edu/archives/sum2017/entries/camus/. ↩
-
Tom Lawrence, ‘Evening Internet “Rush-Hour” Affects Broadband Users’, The Independent, 16 November 2011, sec. Technology, http://www.independent.co.uk/life-style/gadgets-and-tech/news/evening-internet-rush-hour-affects-broadband-users-6262838.html. ↩
-
I also worked with INA’s Groupe de Recherches Musicales (GRM) during the production of Scriptych (see chapter 2). ↩
-
The human-driven perpetual trip is the beginning of Uber’s longer-term plans involving driverless cars. Such vehicles are already being tested with real passsengers in Pittsburgh and San Francisco. Anthony Levandowski, ‘San Francisco, Your Self-Driving Uber Is Arriving Now’, Uber Global, 14 December 2016, https://newsroom.uber.com/san-francisco-your-self-driving-uber-is-arriving-now/. ↩
-
The Eameses made two versionf of Powers of Ten, nearly ten years apart. Both feature the same idea, and near-identical content. The first, A Rough Sketch for a Proposed Film Dealing with Powers of Ten, was made in 1968, whilst a second, longer film made in 1977 is the one commonly referred to as Powers of Ten. Charles Eames and Ray Eames, A Rough Sketch for a Proposed Film Dealing with the Powers of Ten and the Relative Size of Things in the Universe, Film, 1968; Charles Eames and Ray Eames, Powers of Ten, Film, 1977. Both are cited in Charles Eames and Ray Eames, An Eames Anthology: Articles, Film Scripts, Interviews, Letters, Notes, and Speeches, ed. Daniel Ostroff (New Haven, CT: Yale University Press, 2015), 297. ↩
-
Eames and Eames, An Eames Anthology, 297. ↩
-
The scene was actually photographed in Los Angeles, where the Eames studio was located. However, the scene was transplanted to Miami in the 1968 sketch film, and Chicago in the more famous 1977 film. James Hughes, ‘The Power of Powers of Ten’, Slate, 4 December 2012, http://www.slate.com/articles/arts/culturebox/2012/12/powers_of_ten_how_charles_and_ray_eames_experimental_film_changed_the_way.html. This was possible due to the way in which the still photographs and artworks were put together. See Figure 3-31. ↩
-
Eames and Eames, Powers of Ten, 1977. ↩
-
Eames and Eames, An Eames Anthology, 383. Original emphasis. ↩
-
A. M. Turing, ‘On Computable Numbers, with an Application to the Entscheidungsproblem’, Proceedings of the London Mathematical Society 42, no. 2 (1936): 230–65. ↩
-
I first became aware of the principle of film being a succession of images thanks to a visit to the Museum of the Moving Image in New York, aged 10, and have been fascinated with the medium ever since. ↩
-
The hypertext idea has long been associated with Vannevar Bush’s article As We May Think. Bush envisioned a machine called a Memex, a ‘mechanised private file and library’ where people could browse their own catalogue of materials, which would link in relevant places to other related articles. Vannevar Bush, ‘As We May Think’, The Atlantic, 1945, http://www.theatlantic.com/magazine/archive/1945/07/as-we-may-think/303881/?single_page=true. ↩
-
Some film-makers have experimented with different frame-rates; most notably Peter Jackson with his recent interpretation of The Hobbit, which was shot at 48fps. Peter Jackson, The Hobbit: An Unexpected Journey, Adventure, Fantasy, (2012). ↩
-
The recent advent of digital film and its associated compression has all but eliminated the consistent bit-rate. For the sake of reducing file sizes, modern digital film formats such as h.264 or .avi often only encode a keyframe as a complete image, and changes from one frame to the next, rather than a series of individual frames. This means that unlike their analogue equivalents, where every frame occupies the same amount of space, compressed digital films rarely have a consistent bitrate. Whilst it is possible to encode films as a stream of images, the conventions of lossy image compression formats, such as JPEG, mean that each image itself has a different file size. Within digital cinema photography, many of the professional cameras, manufactured by companies such as RED and BlackMagic, offer the option to shoot film as a series of uncompressed RAW images; this gives film-makers greater flexibility to make edits in post-production, and is a digital equivalent of shooting on celluloid. ↩
-
Marvin Minsky, ‘Steps toward Artificial Intelligence’, Proceedings of the IRE 49, no. 1 (January 1961): 11, doi:10.1109/JRPROC.1961.287775. ↩
-
This was presented to an audience at the launch of the Pavillon residency programme at the Palais de Tokyo’s Tokyo Arts Club evening on 25th November 2015. ↩
-
CSV files are a lightweight means to store arrays of information, akin to a spreadsheet. They can be converted to numerous data types, including databases and spreadsheets. Data is stored in plain text format, with each value separated by a comma and a new line per entry. Processing Foundation, Processing 2.2.1, version 2.2.1, Mac OS X (Processing Foundation, 2014), http://www.processing.org. ↩
-
Alfred Hitchcock, Psycho, Horror, Mystery, Thriller, (1960). ↩
-
I had previously used footage from the Prelinger archives in the development of Nybble: see chapter 2. I used a basic Python CURL script to list, then download all of the available Prelinger files from the https://archive.org website in an identical format. ↩
-
The corporate videos included Computer and the Mind of Man, as used in the Nybble dancer-recruitment video. Richard Moore, Computer And The Mind Of Man: Logic By Machine (KQED-TV, National Educational Television, 1962), https://archive.org/details/Logic_by_Machine. ↩
-
Douglas Gordon, 24 Hour Psycho, Film, installation, 1993, http://www.mediaartnet.org/works/24-hour-psycho/; Don DeLillo, Point Omega: A Novel (Pan Macmillan, 2010). ↩
-
The entire premise of the documentary is that Gordon himself is hard to track down. It is shot in a style rarely found in art documentaries today – brash, self-deprecating, irreverent and insincere – the hallmarks of the Young British Artists. Ewan Morrison, ‘24 Hour Psycho’, Ex-S (Scotland: BBC Scotland, 1996), https://www.youtube.com/watch?v=9V0PTNgsQDY. ↩
-
Douglas Gordon and Klaus Peter Biesenbach, Douglas Gordon: Timeline (The Museum of Modern Art, 2006), 292. ↩
-
I am indebted to Amy Butt and David Roberts for their support and clear minds during this chaotic screening. ↩